

해당 포스트에서는 DETR : End-to-End Object Detection with Transformers 논문 리뷰를 진행해보겠습니다.
Ⅰ. Abstract
DETR은 object detection 문제를 해결하기 위해 제안된 모델입니다. 기존 detection 모델과 달리 anchor box의 크기와 갯수를 사전에 정의하는 과정, RoI 추출 하는 과정이 없고 NMS와 같이 중복된 bounding box를 제거하는 과정 또한 없습니다. 한 마디로 정리하자면 DETR은 기존 모델과 달리 인간의 개입을 줄인 object detection model이라고 할 수 있습니다.
이와 더불어 DETR은 transformer의 encoder-decoder 구조를 가져와 사용하였고 모델의 단순화, Faster RCNN과 동등한 정확성과 성능을 보여주었습니다. 또한 object detection 뿐만 아니라 panoptic segmentation으로의 확장도 쉽게 가능함을 보여주었습니다.
해당 포스트에서는 DETR의 핵심만을 간단하게 살펴보고 DETR의 hyper parameter와 실험 결과와 같이 부수적인 것들은 설명하지 않으니 자세한 내용은 논문을 참고해주시면 될 것 같습니다.
Ⅱ. Direct Set Prediction
DETR에서 가장 핵심적인 부분이라고 할 수 있는 direct set prediction에 대해서 알아보겠습니다. DETR은 object detection 문제를 direct set prediction 문제로 새롭게 바라봤습니다. DETR은 모든 객체를 한 번에 예측하며, 예측된 객체와 ground truth의 이분 매칭(bipartite matching)을 통해 direct set prediction 문제를 해결합니다.
논문에서 정확히 direct set prediction이 무엇이다라고 이야기 하지 않았지만 모델의 구조와 학습을 위한 loss function만 살펴보더라도 direct set prediction이 무엇인지 알 수 있을 것 같습니다.
먼저 direct set prediction이 DETR에서 핵심인 이유를 살펴보겠습니다. Direct set prediction 문제를 해결함으로써 anchor box 정의 및 할당, NMS와 같은 작업들을 사용하지 않고 객체를 검출할 수 있게 되었습니다. 사실 anchor box를 정의하고 할당하고 RoI를 추출하고 NMS를 거치는 이러한 과정이 기존의 object detection model들을 복잡하게 만드는 과정 중 하나였습니다. 그러나 이러한 과정이 DETR에서는 필요하지 않기 때문에 모델의 구조가 굉장히 단순해 졌고 이전 모델에 비해서 보다 완벽한 end-to-end 학습을 할 수 있게 되었습니다.
다음으로는 DETR 모델이 direct set prediction 문제를 해결하기 위해 어떻게 구성되어 있는지 알아보겠습니다. DETR 모델은 (ⅰ) 예측된 box와 ground truth 사이의 1대1 매칭을 강제하는 set prediction loss, (ⅱ) 객체들의 집합을 예측하고 객체들의 관계를 모델링하는 구조가 필요합니다.
Set prediction loss
Transformer의 decoder input으로 주어진 object query 갯수만큼의 예측된 bounding box와 class를 hungarian matching을 통해 ground truth와 matching을 하게 됩니다. 이 때 사용되는 loss term은 아래와 같습니다.
\[\mathcal{L}_{Hungarian}(y,\hat{y}) = \sum^N_{i=1}[-\log{\hat{p}_{\sigma(i)}(c_i)} + \mathbb{1}_{\{c_i\neq\varnothing\}}\mathcal{L}_{box}(b_i,\hat{b}_{\hat{\sigma}(i)})]\]위의 수식에 필요한 수식들은 아래와 같습니다.
\[\begin{align} \hat{\sigma} &= \underset{\sigma\ \in\ \mathfrak{S}_N}{argmin}\sum^N_i\mathcal{L}_{match}(y*i, \hat{y}*{\sigma(i)}) \\ \mathcal{L}_{match}(y_i, \hat{y}_{\sigma(i)}) &= -\mathbb{1}_{\{c_i\neq\varnothing\}}\hat{p}_{\sigma(i)}(c_i) + \mathbb{1}_{\{c_i\neq\varnothing\}}\mathcal{L}_{box}(b_i,\hat{b}_{\sigma(i)})\\ \mathcal{L}_{box}(b_i,\hat{b}_{\sigma(i)}) &= \lambda_{iou}\mathcal{L}_{iou}(b_i,\hat{b}_{\sigma(i)}) + \lambda_{L1}||b_i - \hat{b}_{\sigma(i)}||_1 \end{align}\]DETR architecture
DETR의 구조는 매우 단순합니다. 아래의 두 개의 그림으로 모든 것이 설명가능합니다.
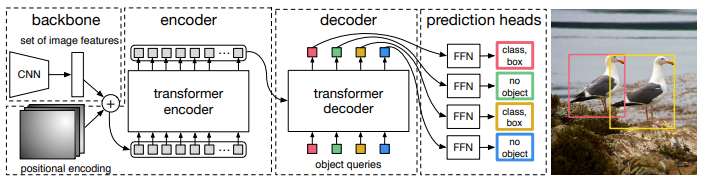
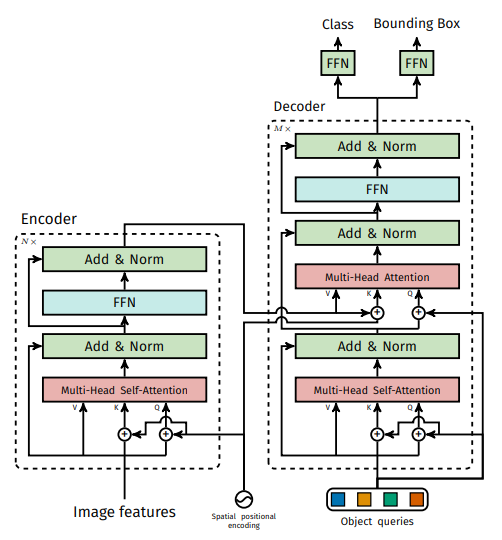
DETR architecture의 핵심을 뽑으면 아래와 같습니다.
- CNN과 transformer 결합
- Transformer encoder-decoder 구조
- Object query(positional encoding)의 병렬화
- FFN을 통해 객체의 클래스와 bounding box 정보 예측
저의 결론
🤔 Object detection 분야를 처음 공부하는 사람들에게 가장 큰 진입 장벽이라고 생각되는 부분이 저는 RoI 추출과 feature map의 scale 차이에서 오는 좌표 변환과 같은 것들이라고 생각이 듭니다. 물론 NMS도 빠지지 않는 것 같습니다. 그러나 transformer, CNN 모델의 구조만 알면 DETR은 object detection 문제를 해결하는 모델임에도 불구하고 이전 모델에 비해서 간단해진 것은 틀림 없는 것 같습니다. 그런 점에서 DETR은 저에게 있어서는 신선한 논문이였던 것 같습니다.
🤔 좋은 시도임에도 불구하고 여전히 완벽한 end-to-end가 아닌 것도 생각해 볼 필요가 있을 것 같습니다. 학습이야 end-to-end로 이뤄지기는 하지만 중간에 hungarian matching이 들어감으로써 완벽한 end-to-end라고 하기에는 부족함이 있는 것 같습니다. 이 점이 아쉽기는 하지만 detection 문제를 해결하는 모델 중에서는 가장 end-to-end에 근접한 모델이 아닌가 싶습니다.