

해당 포스트에서는 Sequence to Sequence(Seq2Seq) 논문 리뷰를 진행해보겠습니다.
Abstract
해당 논문은 기계 번역과 관련된 논문으로 baseline으로 잡은 SMT(Statistical Machine Translation)와 비교하면서 어떤 점이 개선되었는지 설명하고 있습니다.
해당 논문에서 제시한 방법에는 크게 3가지가 있습니다.
⭐ General end-to-end approach to sequence learning
⭐ Deep LSTM
⭐ Reverse the oreder of the words in all source sentences
1. Datasets
해당 논문에서 실험에 사용한 datasets은 WMT’14로 다양한 언어를 쌍을 지어 machine translation을 학습 및 평가를 할 수 있도록 한 datasets입니다. 여기서 영어 문장을 프랑스 문장으로 번역하는 datasets를 사용했습니다. 고정된 단어를 사용하기 위해 영어 문장에서는 가장 빈번하게 등장하는 16만개의 단어를, 프랑스 문장에서는 가장 빈번하게 등장하는 8만개의 단어만을 사용했으면 여기에 포함되지 않는 단어들은 UNK token(unknown token)으로 대체하여 사용했습니다.
추가적으로 baseline model인 SMT와 비교하기 위해 1000-best lists from baseline SMT를 사용했습니다.
2. Model
2.1 General end-to-end approach to sequence learning
해당 논문에서는 input sequence와 output sequence의 다른 두 가지 LSTM을 사용했습니다. 처음 해당 논문을 접하신다면 해당 부분이 이해가 어려울 수 있을 것 같습니다. 🥲
그림으로 보신다면 해당 부분에 이해가 조금 더 쉬울 것 같습니다. 먼저 하나의 LSTM으로 번역 하는 경우를 보여드리겠습니다.
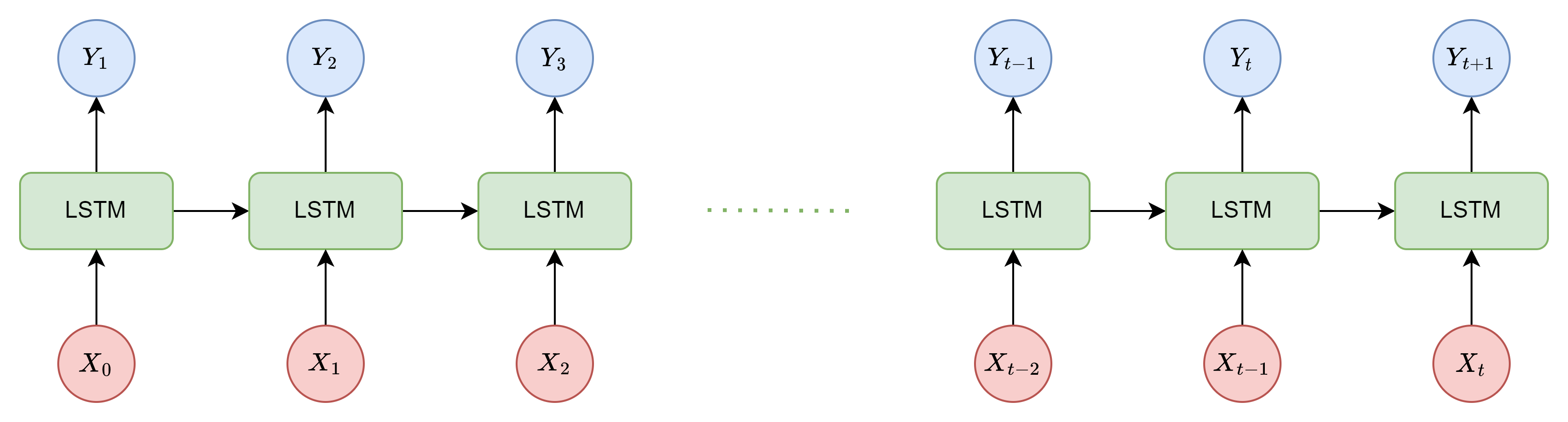
그 다음 해당 논문에서 번역을 어떻게 하는지 보여드리겠습니다. 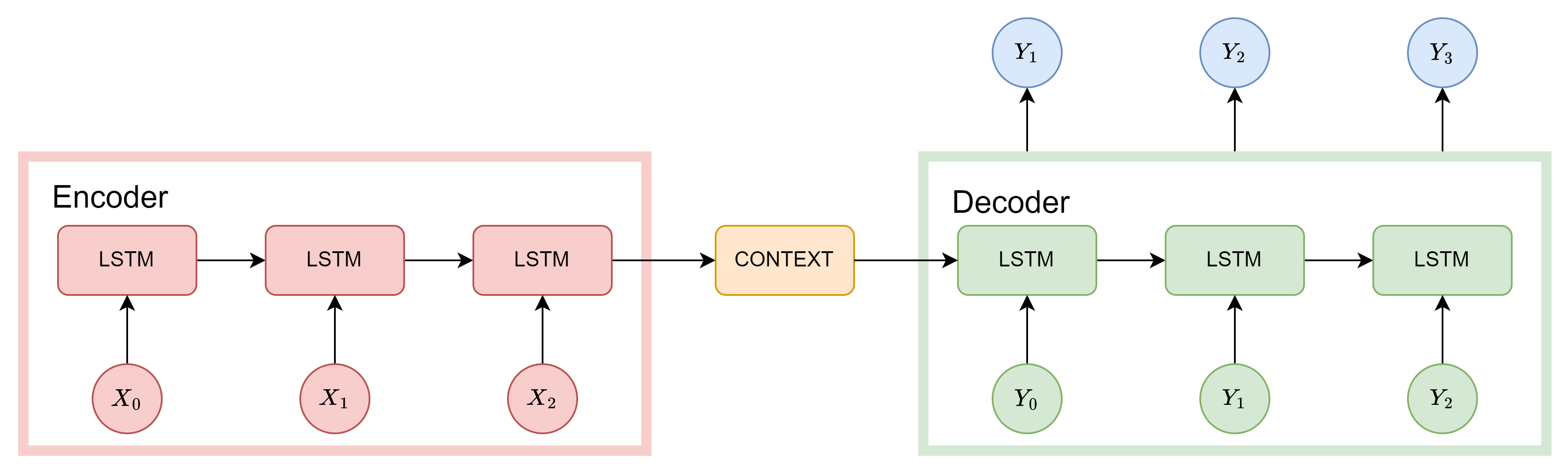
첫 번째 사진과 두 번재 사진에 가장 큰 차이는 LSTM 두 개의 block을 사용하면서 encoder-decoder 구조를 사용한다는 것 입니다. 이전에는 이전의 단어와 더 이전의 정보들을 통해 다음 나올 단어를 예측했다면 해당 논문에서는 하나의 문장을 하나의 vector(context vector라 부름)로 encoding을 하고 이를 하나씩 decoding 하면서 번역을 진행합니다. 이러한 구조를 가지면 input sequence의 길이와 output sequence의 길이가 달라져도 되는 장점이 있습니다.
🔎 기존의 LSTM에서 어떤 정보를 context vector로 사용하는지 궁금하실 수 있을 것 같습니다. 해당 논문에서는 encoder의 마지막 lstm에서 나온 hidden state를 context vector로 사용합니다.
2.2 Deep LSTM
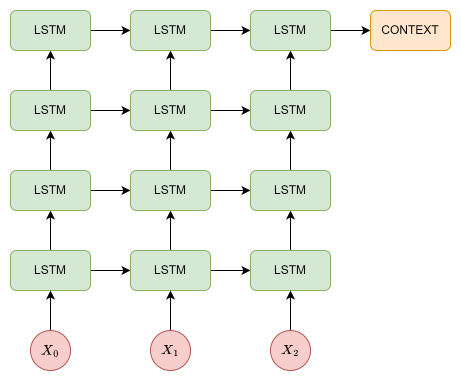
해당 논문에서는 single LSTM 대신 deep LSTM을 사용했으며 deep LSTM이 shallow LSTM을 크게 능가하는 것을 발견하여 4개의 계층이 있는 LSTM을 사용했습니다.
🤔 해당 논문에서는 deep LSTM을 사용하면서 얻는 직접적인 실험 결과를 언급하지는 않았지만 deep LSTM을 사용하므로써 더 많은 weight들이 학습되면서 학습에 사용되지 않은 단어들이 등장했을 때 이를 대처하는 능력이 높아지지 않았을까 생각합니다.
2.3 Reverse the oreder of the words in all source sentences
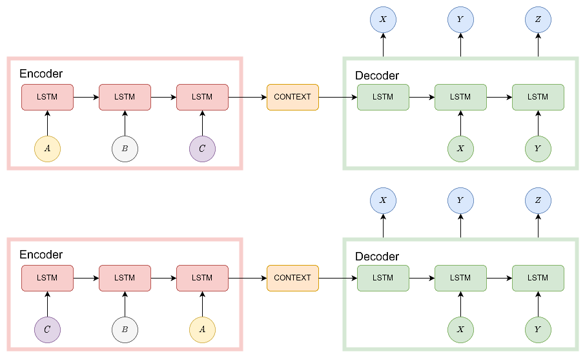
해당 부분이 해당 논문에서 가장 강조하는 부분이 아닐까 합니다. Source 문장의 단어를 반전 시켜 입력하고 target 문장의 단어는 반전 시키지 않고 그대로 학습했을 때 더 좋은 결과를 얻을 수 있었다고 합니다.
LSTM의 경우 RNN과 달리 long term dependency를 해결했지만 source 문장의 단어 순서를 반전 시켰을 때 더 쉬운 번역과 더 정확한 번역이 일어남을 해당 논문 저자들이 발견했다. 이에 대한 정확한 이유를 저자들도 설명할 수 없지만 저자들은 “Source 문장과 target 문장에서 대응하는 단어들 간의 평균 거리는 변하지 않지만 source 문장의 단어 순서를 반전 시킴으로써 몇 단어들의 거리가 근접하므로 최소 시간 지연(minimal time lag)이 줄어들어 성능이 향상했다”라고 생각한다고 합니다.
저자들의 생각대로 한다면 target 문장의 앞부분은 잘 맞추고 뒤로 갈수록 못맞춰야 합니다. 그러나 이렇게 반전된 문장으로 학습된 LSTM은 반전되지 않은 문장으로 학습된 LSTM보다 긴 문장에서 더 좋은 성능을 보였습니다.
이러한 결과를 확인한 저자들은 입력문장을 반전시켜 학습하는 것이 더 좋은 메모리 활용도를 보여주기 떄문이라고 말하고 있습니다.
3. Evaluation
해당 논문에서는 machine translation을 평가할 때 가장 많이 사용되는 BLEU방법을 사용했습니다.
해당 논문의 결과가 WMT’14 SOTA를 능가하지는 못했습니다. 그러나 pure neural translation system이 학습되지 않은 단어를 처리할 수 없음에도 불구하고 대규모 machine translation 작업에서 phrase-based SMT baseline을 상당한 차이로 능가한 것은 처음이라고 합니다.
1000-best lists from baseline SMT를 사용해 rescoring 했을 때 결과는 다음과 같습니다.
SMT baseline
BLEU : 33.3
WMT’14 SOTABLEU : 37.0
Seq2SeqBLEU : 36.5
4. Conclusion
해당 논문을 읽으면서 생각의 전환이 큰 변화를 불러올 수 있다는 것을 알 수 있었던 것 같습니다. 그러나 저자들도 정확한 이유를 찾지 못해서인지 완전히 해결되지 않는 부분들도 있었던 것 같습니다. 그럼에도 불구하고 encoder-decoder 구조를 제안함으로써 이후 machine translation 분야에 큰 변화가 왔다는 것은 분명한 것 같습니다. 아직 attention 논문을 읽어보지 못했지만 해당 논문이 시발점인 것은 틀림없을 것 같습니다.