

해당 포스트에서는 An image is worth 16X16 words: Transformers for image recognition at scale(ViT) 논문 리뷰를 진행해보겠습니다.
Ⅰ. Abstract
해당 논문은 NLP분야의 transformer를 computer vision 분야에서 사용할 수 있도록 고안된 모델 ViT에 대한 논문입니다. ViT는 원본 이미지에 변형을 가하지 않고 그대로 input data로 사용하되 CNN인 아닌 full self-attention 구조를 computer vision에 사용가능하도록 만들었습니다.
해당 논문에서는 classification task에 대해서만 다루었으며 다른 computer vision 분야인 object detection, semantic segmentation과 같은 분야에 대해서는 추후 연구로 남겼습니다.
또한 많은 양의 data에 대해 pre-train 하고 적은 data로 fine-tune 했을 때 CNN SOTA보다 더 좋은 결과를 보여주면서 computational cost 측면에서도 효율적임을 해당 논문에서 밝혔습니다.
해당 블로그에서는 ViT의 구조를 간단하게 정리를 해보고 위에서 말한 ViT의 특징들에 대한 실험들을 위주로 정리를 해보겠습니다. 이 외의 다른 내용들은 논문을 직접 참고해보시면 될 것 같습니다.
Ⅱ. ViT 구조
먼저 ViT를 간단하게 잘 설명하는 이미지를 보여드리겠습니다.
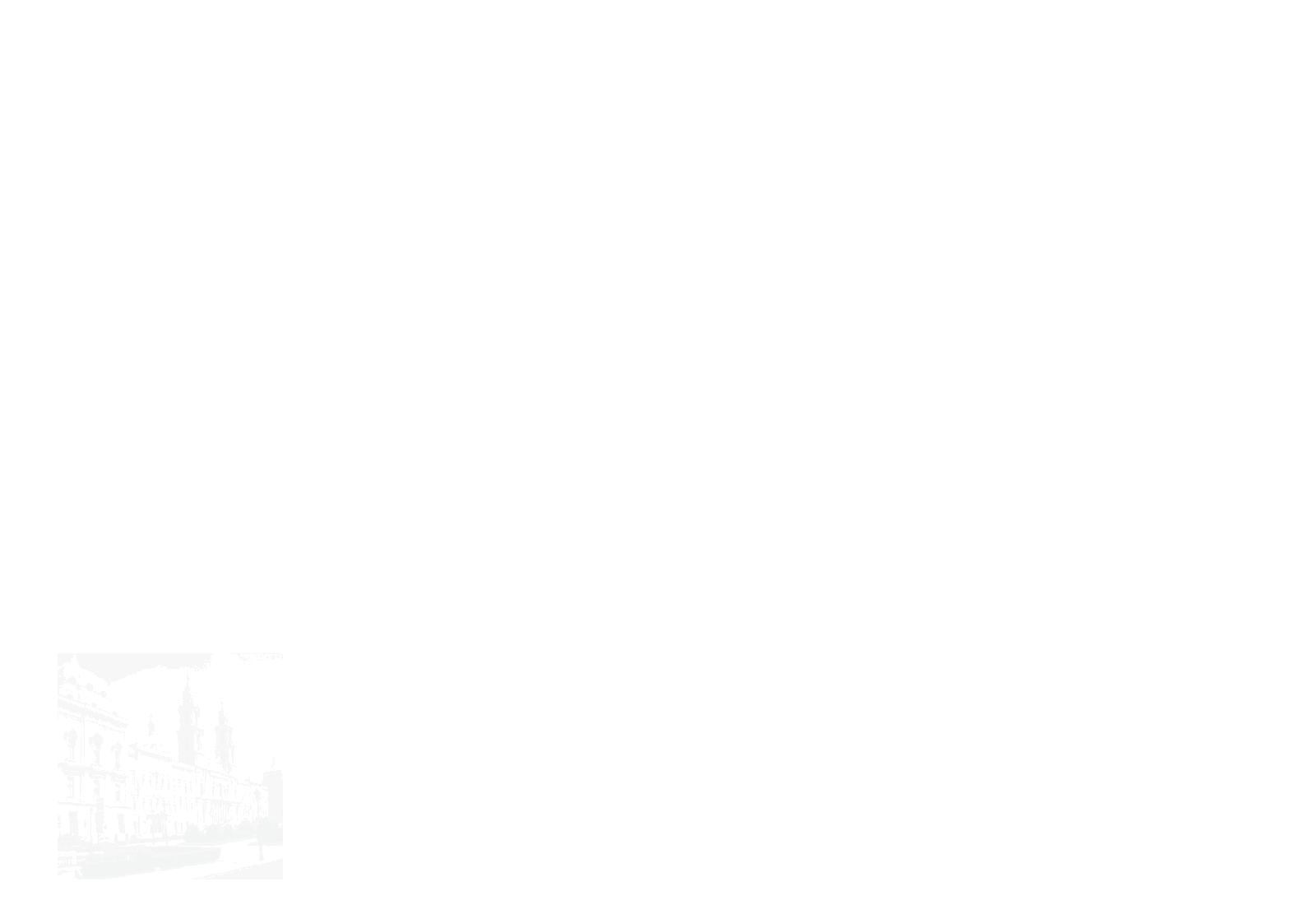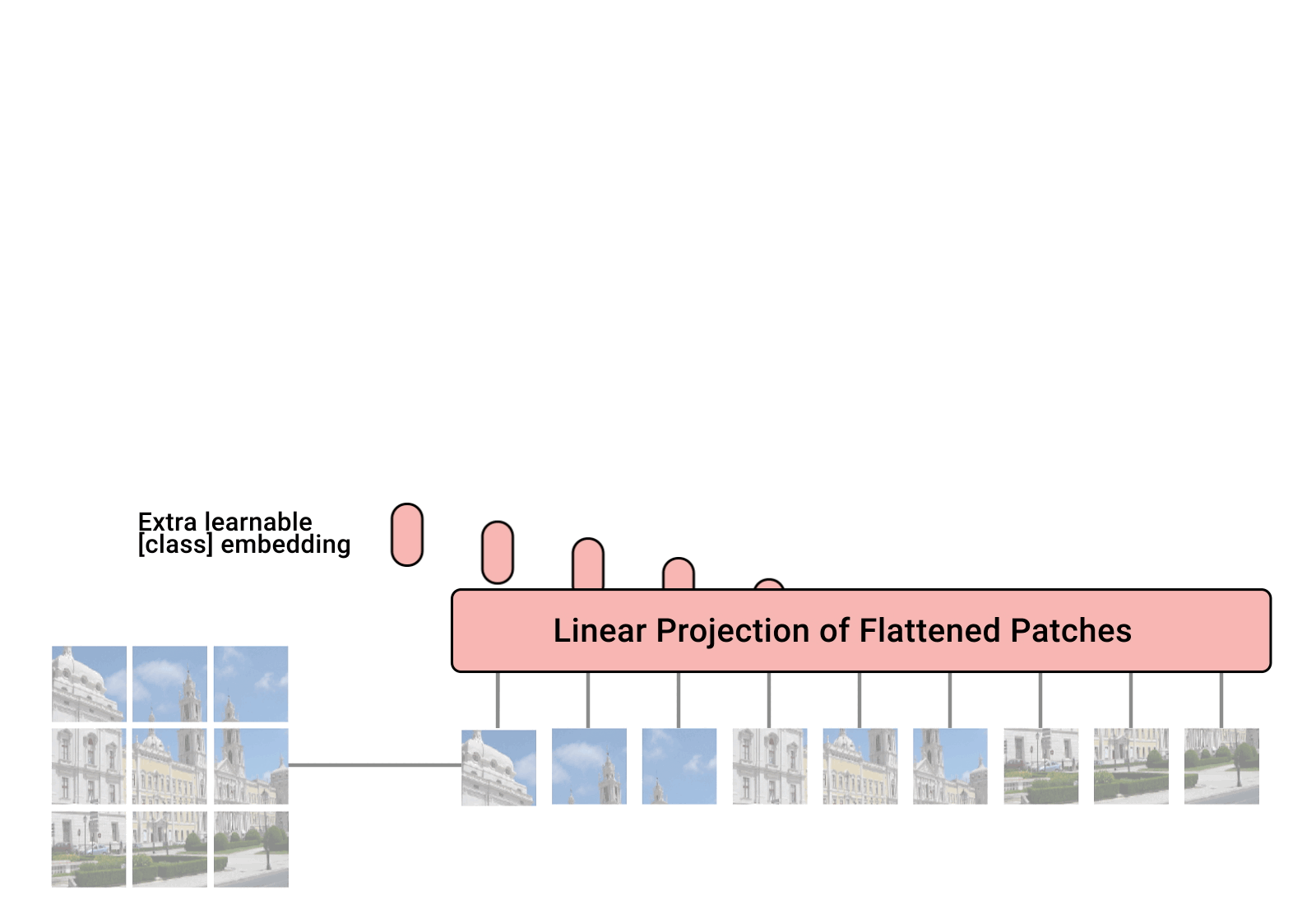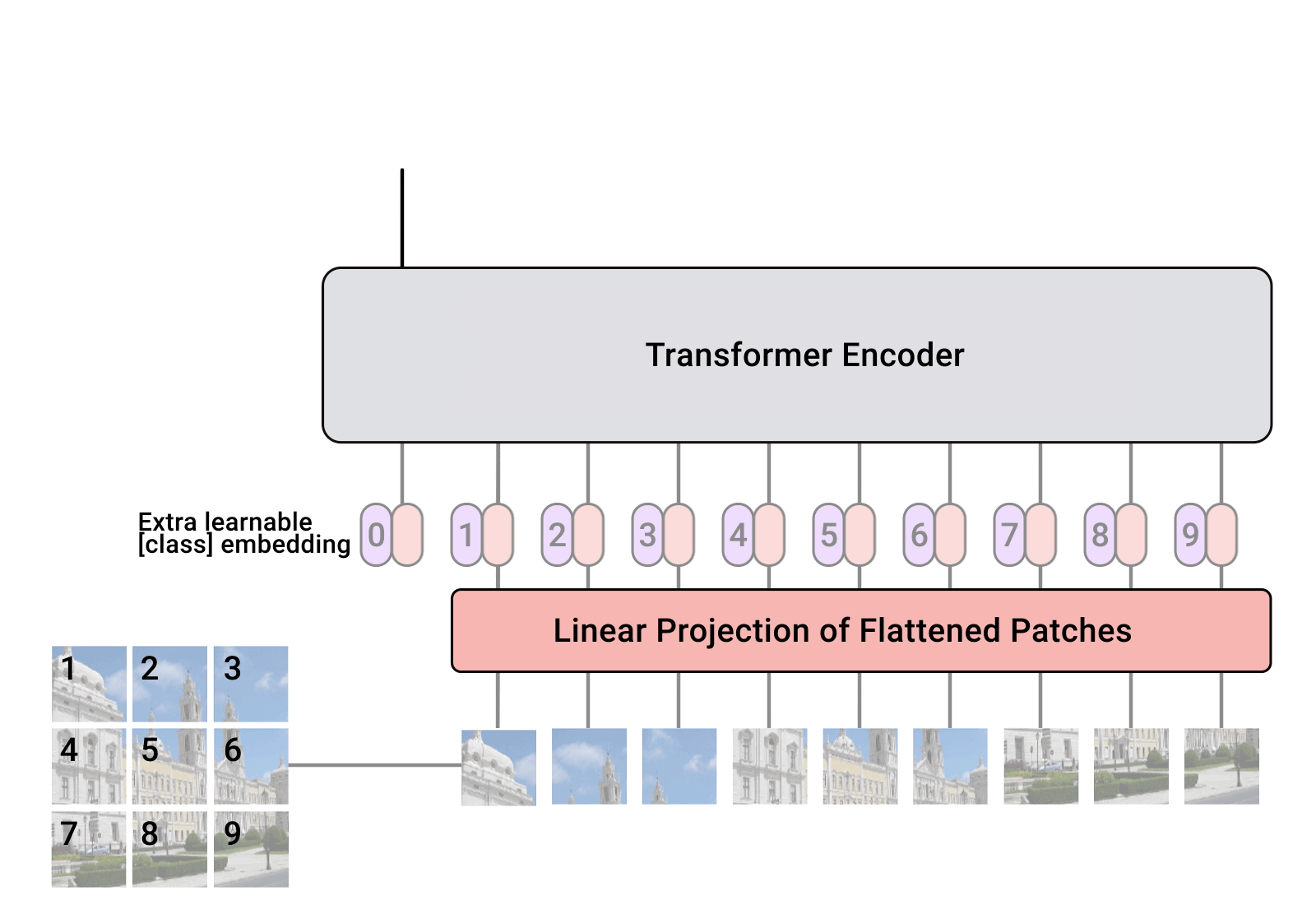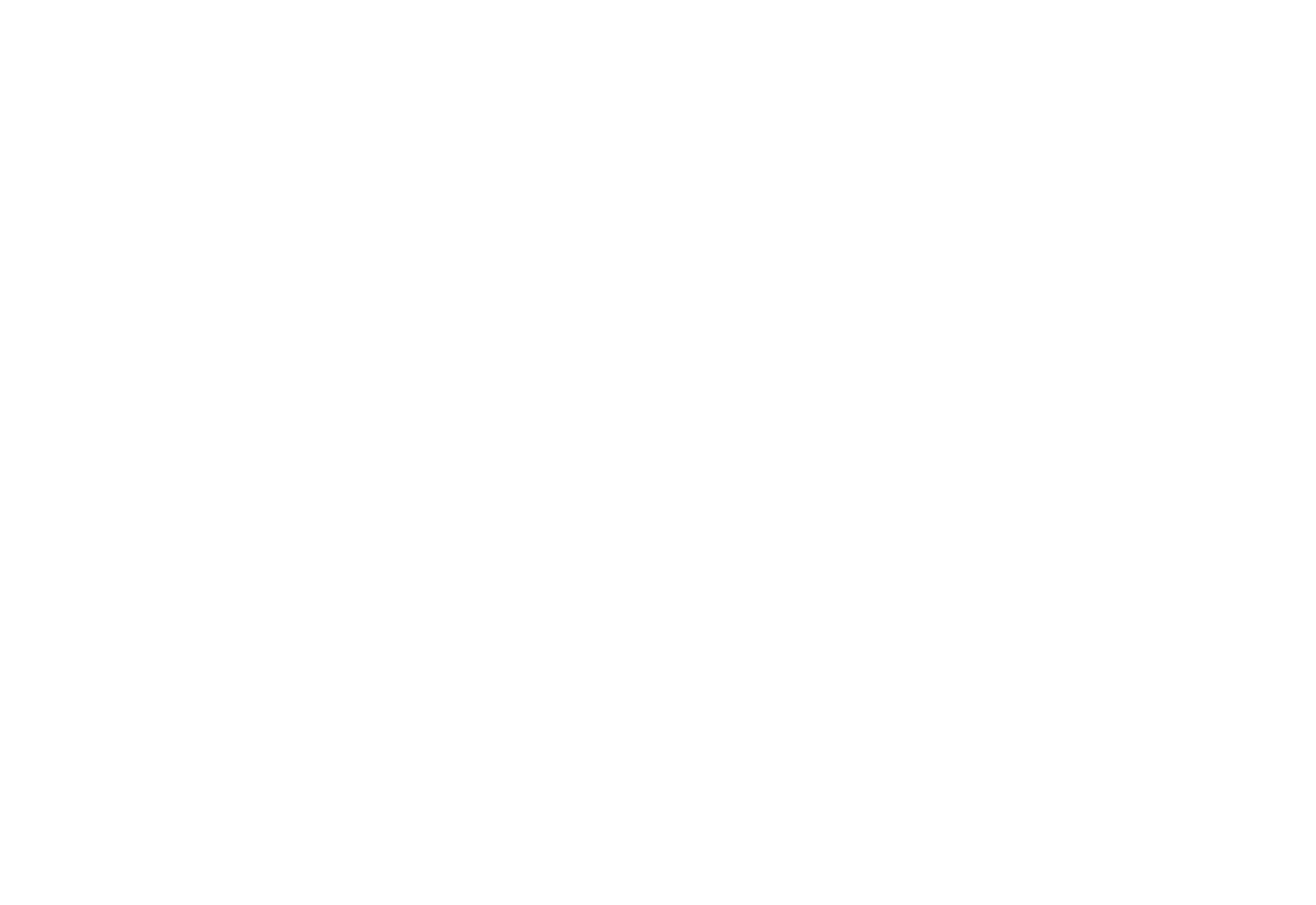 출처: https://github.com/lucidrains/vit-pytorch
출처: https://github.com/lucidrains/vit-pytorch
ViT는 NLP 분야의 transformer 구조를 그대로 가져오고자 했습니다. 따라서 transformer의 구조를 아시면 ViT의 구조를 이해하는 부분에 있어서는 큰 어려움이 없을 것이라 예상합니다. 다만 NLP 분야의 transformer와 다른 점이라고 한다면 크게 encdoer-decoder 구조가 아닌 encoder만 사용한다는 점과 CLASS token이 추가된다는 점인 것 같습니다. Image patch와 같이 이미지에 맞게 변경된 부분이 있기는 하지만 최대한 NLP 분야의 transformer의 구조를 따라가고자 한 것이 눈에 띄는 모델 구조입니다.
ViT input
Patch Embedding
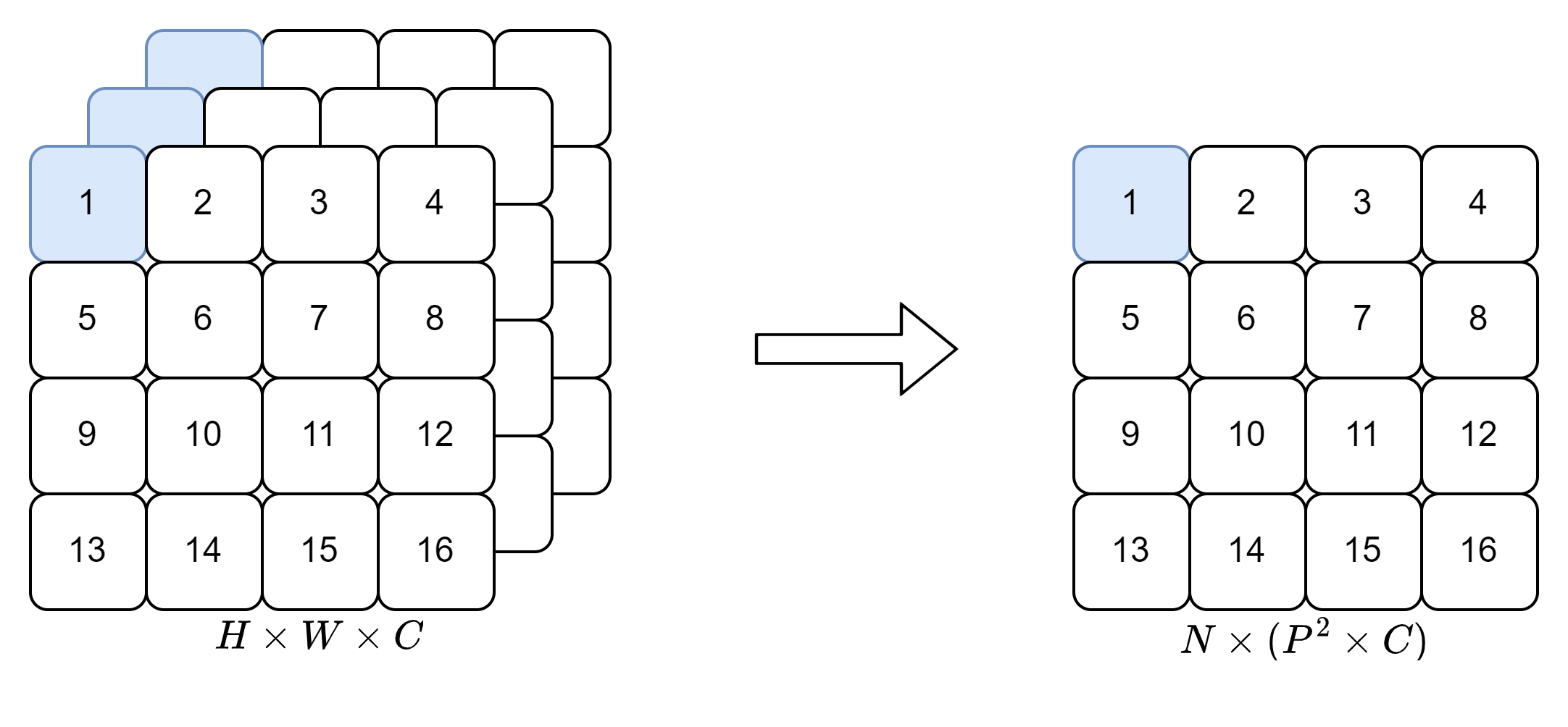
이미지를 동일한 크기로 나눠줍니다.
- Patch의 크기 : $P$
- Patch의 갯수 : $N = HW/P^2$
- Channel 수 : $C$
![]()
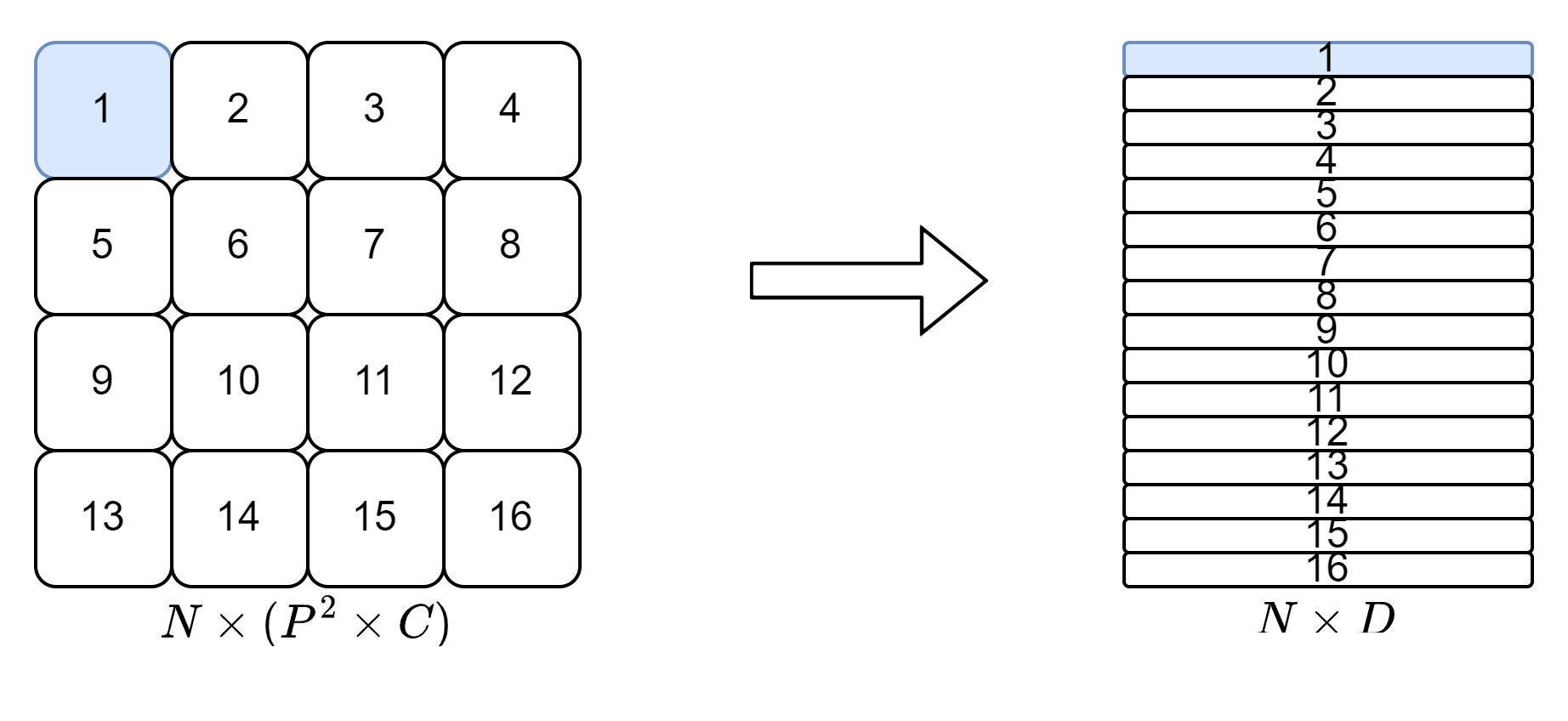
Latent vector size $D$로 mapping 시켜줍니다.
![]()
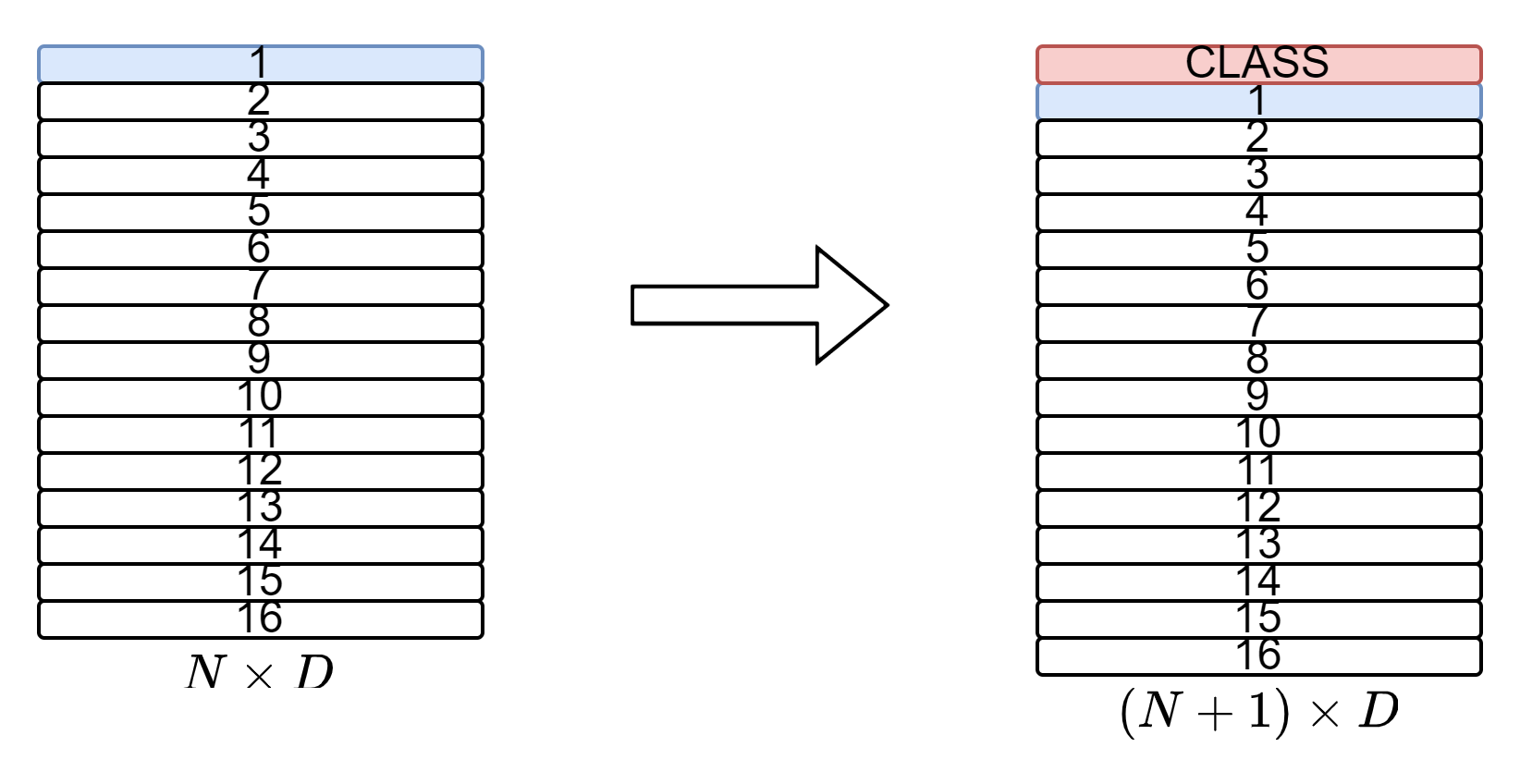
CLASS Token 추가
이미지의 class를 구분하기 위해 CLASS Token을 $D$차원의 vector로 추가해줍니다.
![]()
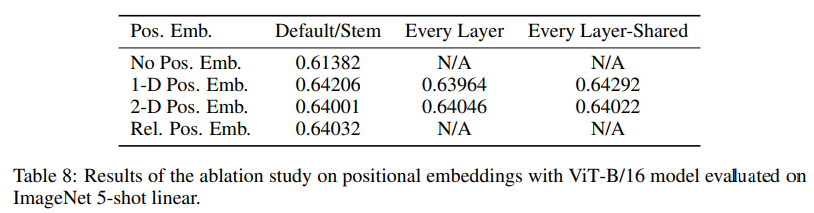
Position embedding
Position embedding을 모델에 주입하는 위치, 방법을 다르게하여 더 좋은 성능을 보이는 모델을 선택하고자 했으나 저자들의 실험 결과 position embedding이 모델에 주입하기만 한다면 모델에 주입하는 위치는 큰 상관이 없었고 2D-positional embedding와 relative positional embedding을 실험했으나 큰 성능 향상을 발견하지 못해 일반적으로 사용하는 1D-positional embedding을 사용했습니다.
![]()
한 눈에 보기
Patch Embedding, CLASS Token, position embedding을 수식으로 나타내면 아래와 같습니다.
\[\mathbf{z}0 = [\mathbf{x}{\text{class}}; \mathbf{x}^1_p\mathbf{E}; \mathbf{x}^2_p\mathbf{E};\cdots ; \mathbf{x}^N_p\mathbf{E}] + \mathbf{E}{pos},\quad \mathbf{E} \in \mathbb{R}^{(P^2\cdot C)\times D},\ \mathbf{E}{pos} \in \mathbb{R}^{(N+1)\times D}\]Patch Embedding, CLASS Token, position embedding을 그림으로 나타내면 아래와 같습니다.
![]()
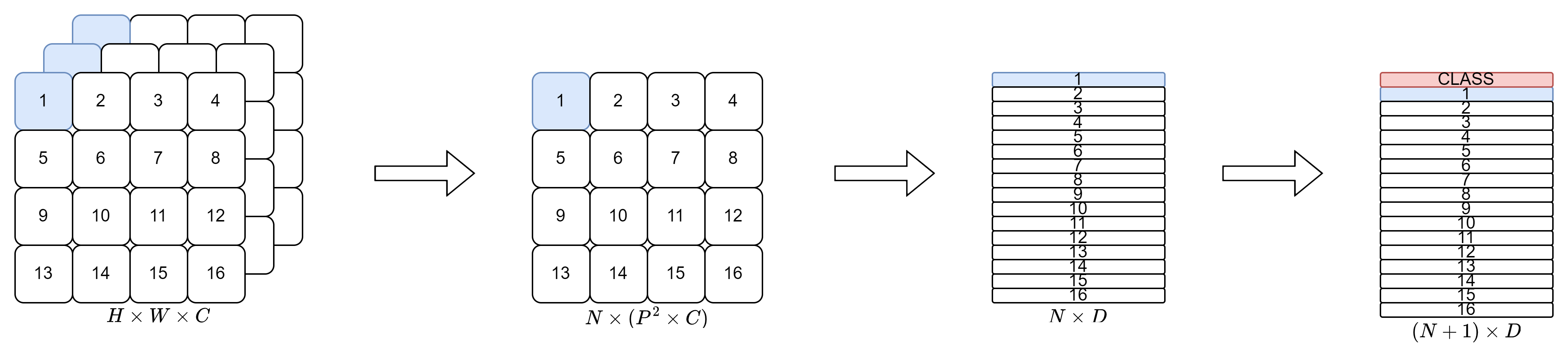
Encoder & Classification
Input의 형태를 NLP분야의 transformer input의 형태와 똑같이 만들었기 때문에 이후 계산 과정은 크게 다른 것이 없으므로 수식으로만 알아보고 넘어가겠습니다. 아래의 수식은 input부터 classification까지의 과정을 모두 나타낸 것입니다.
\[\begin{aligned} &\mathbf{z}0 = [\mathbf{x}{\text{class}}; \mathbf{x}^1_p\mathbf{E}; \mathbf{x}^2_p\mathbf{E};\cdots ; \mathbf{x}^N_p\mathbf{E}] + \mathbf{E}{pos},\quad &&\mathbf{E} \in \mathbb{R}^{(P^2\cdot C)\times D},\ \mathbf{E}{pos} \in \mathbb{R}^{(N+1)\times D}\quad&(1)\\ &\mathbf{z}^\prime_\ell = \text{MSA}(\text{LN}(\mathbf{z}_{\ell-1}))+\mathbf{z}_{\ell-1}, &&\ell = 1 \dots L\quad&(2)\\ &\mathbf{z}_\ell = \text{MSA}(\text{LN}(\mathbf{z}^\prime_{\ell}))+\mathbf{z}^\prime_{\ell}, &&\ell = 1 \dots L\quad&(3)\\ &\mathbf{y} = \text{LN}(\mathbf{z}^0_L) && &(4)\\ \end{aligned}\]Ⅲ. ViT와 CNN
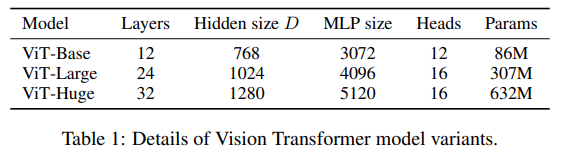
해당 논문에서 CNN과의 성능을 비교하기 위해 사용한 모델은 크게 3가지 입니다.
ViT
- ViT-B/P : Patch의 크기가 $P$인 ViT Base 모델
- ViT-L/P : Patch의 크기가 $P$인 ViT Large 모델
- ViT-H/P : Patch의 크기가 $P$인 ViT Huge 모델
🔎 Transformer의 sequence length는 $P^2$에 반비례하므로 $P$가 작을수록 즉, patch가 pixel에 가까워질수록 계산 비용이 많이 듭니다.
![]()
ResNet(BiT)
- BiT : Big Transfer에서 사용한 ResNet을 그대로 사용
- 단, batch normalization을 group normalization으로 변경
- Standardized convolutions 사용
Hybrid
- Patch size가 1인 ViT에 intermediate feature map 공급
- Intermediate feature map
- ResNet50의 4단계 출력값
- ResNet50의 4단계를 제거하고 3단계의 동일한 수의 층을 배치(전체 층 수 유지)한 확장된 3단계의 출력
위의 3가지 모델을 통해 저자들은 CNN보다 ViT가 계산적 측면 그리고 성능면에서 좋은 것을 밝히고자 했습니다. 하지만 적은 data로 학습하여 평가를 할 때 CNN이 훨씬 좋은 성능을 보였는데 이것은 CNN의 inductive bias(localization, translation equivariance)가 ViT에는 적기 때문이라고 저자들은 말했습니다. 그러나 많은 data로 학습하면 직접 이미지들의 패턴을 학습하게 되므로 inductive bias와 상관없이 CNN보다 좋은 결과를 내는 것을 확인했습니다.
또한 많은 data로 학습을 한 후 fine-tuning을 하게 되면 CNN보다 계산 비용이 적고 CNN보다 더 좋은 성능을 보이는 것을 알 수 있었습니다.
SOTA 비교
JFT datasets으로 pre-train을 하고 fine-tuning 했을 때 가장 좋은 결과를 얻을 수 있었습니다.
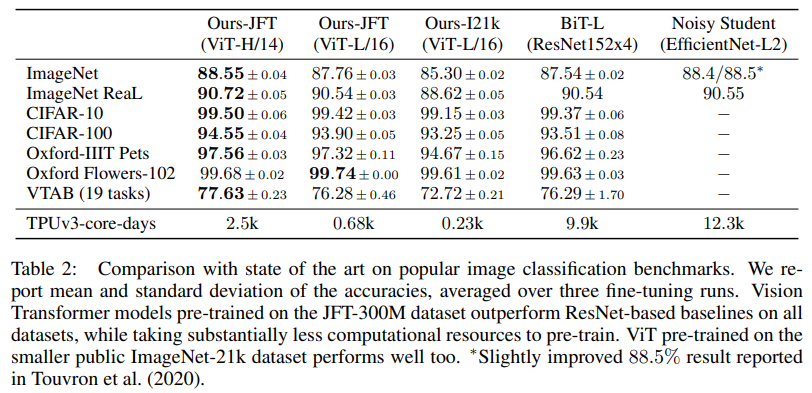
Pre-training 할 때의 dataset size의 중요성
ImageNEt,ImageNet-21k,JFT-300M으로 pre-training을 하고CIFAR-10/100,ImageNet,ImageNet ReaL,Oxford로 fine-tuning 했을 때의 결과를 비교한 실험입니다. 그 중ImageNet으로 fine-tuning 했을 때의 결과를 도표로 살펴보면 pre-train dataset이 커질수록 모델의 사이즈가 커질수록 더 좋은 성능을 보여주고 있음을 알 수 있습니다.![]()
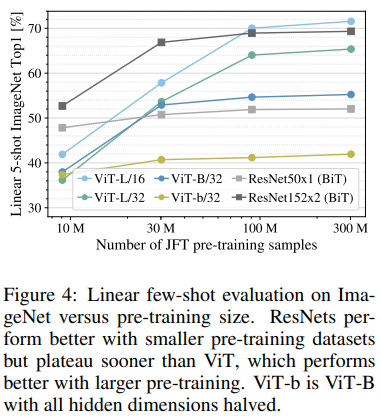
JFT-300M을 random subset으로 나누어 pre-training 할 때ImageNet에 대한 fine-tuning 성능을 5-shot으로 비교했습니다. Datasets의 크기가 작을 때는 CNN의 성능이 훨씬 좋지만 datasets의 크기가 커질수록 ViT의 성능이 CNN의 성능을 능가하는 것을 확인할 수 있습니다.![]()
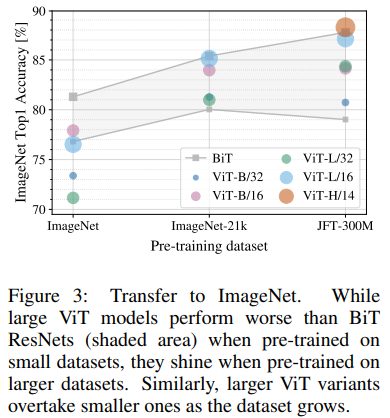
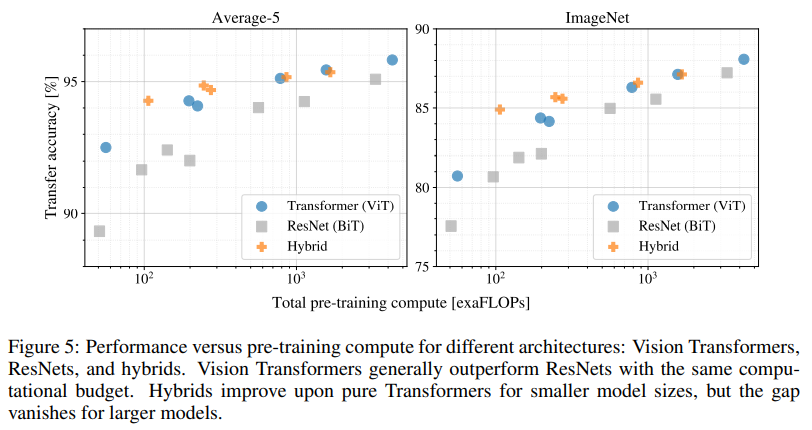
Transfer performance
Pre-training을 하는데 필요한 computational budget과 fine-tuning을 했을 때의 성능 차이를 비교했습니다. 이를 통해 3가지를 알 수 있었습니다.
- ViT는 performance/compute trade-off에서 CNN을 능가합니다.
- 적은 computational budget에서는 hybrid 모델이 약간 뛰어나지만, 큰 ViT에서는 그 차이가 사라집니다.
- ViT는 실험된 하드웨어 범위 안에서 포화되지 않아 향후 확장 가능성이 있습니다.
Attention Distance
Attention distance란 attention weights를 기반으로 정보가 통합되는 이미지 공간의 평균 거리를 말합니다. Attention distance는 CNN의 receptive field와 유사합니다. ViT의 낮은 계층에서 일부 헤드가 이미지의 대부분을 attention 하고 있음을 발견하였고 나머지 헤드들은 작은 attention distance를 가지고 있음을 발견했습니다. 모델의 깊이가 증가할수록 모든 헤드에 대한 attention distance가 증가하였고 network의 출력층과 가까워질수록 대부분의 head들이 token 전반에 걸쳐 광범위하게 attention하는 것을 발견했습니다.

Ⅳ. Conclusion
Paper
- Image recognition에 transformer를 직접 적용하는 방법 탐구했습니다.
- Image-specific inductive biases를 주입하지 않는 대신 iamge patch를 sequence로 해석합니다.
- Large datasets에 대해 pre-training할 때 놀라운 결과를 보여줬습니다.
- Challenges
- 다른 computer vision 분야(detection, segmentation)에 ViT를 적용하는 문제
- Exploring self-supervised pre-training methods
- ViT의 추가적인 확장은 성능 향상으로 이어질 가능성이 높아질 수 있습니다.
저의 결론
🤔 Computer vision 분야에 오직 self-attention만으로 구성된 모델이 처음 사용된 만큼 기존에 지배적이던 CNN과 비교하려는 실험이 주를 이뤘던 논문인 것 같습니다.
🤔 NLP분야와 더불어 CV분야까지 transformer가 적용됨에 따라 transformer의 확장성에 대해 다시 한 번 생각해보게 되는 것 같습니다.